DeepSeek V4 has begun pushing overseas developers to create dedicated high-speed pathways for it.
Just two weeks after its release, the first batch of native infrastructure for V4 has emerged in the open-source community.
This is not just a minor tweak on existing frameworks. It is not a generic GGUF loader; it is not a wrapper for llama.cpp; and it does not support other models at all.
It does one thing:
Run DeepSeek V4 Flash to its fullest on Mac.
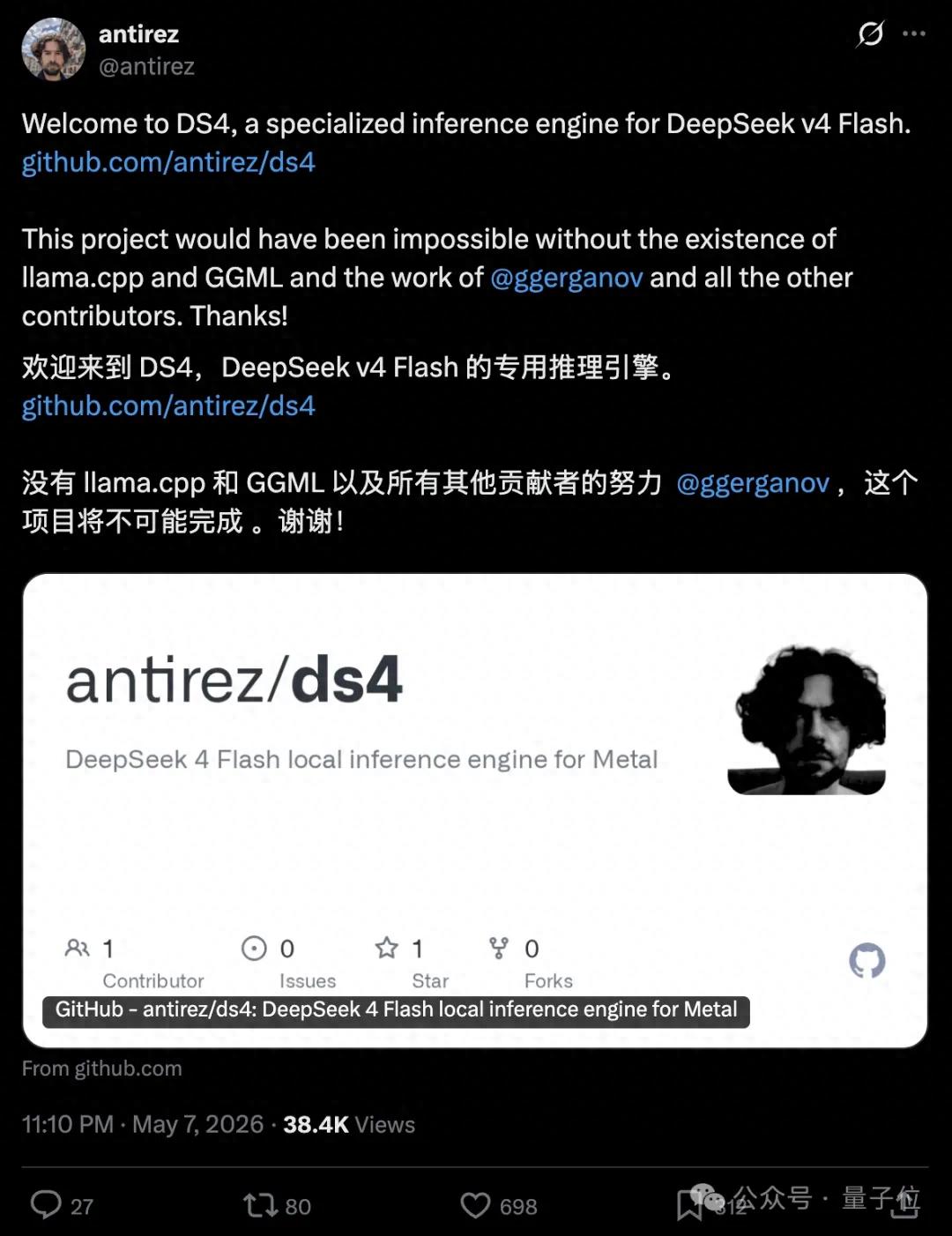
This dedicated pathway is called ds4.c. The developer behind it is quite notable—Salvatore Sanfilippo, better known in the programming world as antirez.
He created Redis (with 74,000 stars on GitHub) and led the development of this globally popular in-memory database for 11 years.
Now, his new project ds4.c is a local inference engine specifically designed for DeepSeek V4 Flash.
Users have already reported running it on a 128GB Mac.
This time, DeepSeek has cleared out Mac inventory once again.
A Local Inference Engine for V4 Flash
On April 24, DeepSeek released the V4 series, with V4 Flash being the efficiency model: 284 billion total parameters, 13 billion active parameters, and a context of 1 million tokens.
Such a scale has almost always been reserved for cloud computing.
Antirez aims to fit it into a Mac, leading to the birth of ds4.c.

This is an inference engine written from scratch using C + Metal.
The entire project consists of just a few files, with C accounting for 55.4%, Objective-C 30.2%, and Metal 13.8%. It is Metal-only, with no runtime, no framework dependencies, and no abstraction layers.
Metal-only.
Metal is Apple’s own graphics and computing API, used to call the GPU on Mac, iPhone, and iPad, akin to CUDA in the Apple ecosystem.
The fact that ds4 only uses Metal means this engine runs solely on Apple Silicon, disregarding Nvidia and AMD graphics cards.
The sole goal of the project is:
To ensure V4 Flash runs locally on Apple machines, not just “can run,” but truly “usable.”
Current test results are quite impressive:
On a 128GB MacBook Pro M3 Max, with 2-bit quantization and 32K context, it pre-fills short prompts at 58.52 tokens/s and generates at 26.68 tokens/s.
Switching to a 512GB Mac Studio M3 Ultra, it achieves 468.03 tokens/s for pre-filling long prompts (11,709 tokens) and generates at 27.39 tokens/s.
For a 284 billion parameter MoE model, this speed is usable on local machines.
How Is This Achieved?
The key lies in three aspects.
First, asymmetric quantization.
Ds4 does not quantize all parameters to 2-bit; instead, it only quantizes the routing of the MoE expert layers, using IQ2_XXS for up/gate and Q2_K for down, which occupy the majority of the model space. Other components, such as shared expert layers, projection layers, and routing layers, retain Q8 precision.
Antirez states directly in the README:
These 2-bit quantizations are no joke; they perform well under coding agents and can reliably call tools.
Second, KV cache moved to disk.
Current LLM agent clients are stateless, sending the entire conversation segment with each request. The approach of general engines is to redo the pre-fill each time.
Ds4’s method writes the KV state to disk, matching token prefixes on subsequent requests, and if matched, loads directly from disk, skipping the pre-fill.
The cache key is the SHA1 hash of the token ID sequence.
This is particularly useful for agents like Claude Code, which send a 25K token initial prompt with each startup; after the first pre-fill, subsequent sessions can directly recover from disk.
Third, built-in compatibility layers for OpenAI and Anthropic APIs.
/v1/chat/completions follows the OpenAI protocol, while /v1/messages follows the Anthropic protocol. Tool calling has also been adapted. The README provides configuration examples for opencode, Pi, and Claude Code agent clients.
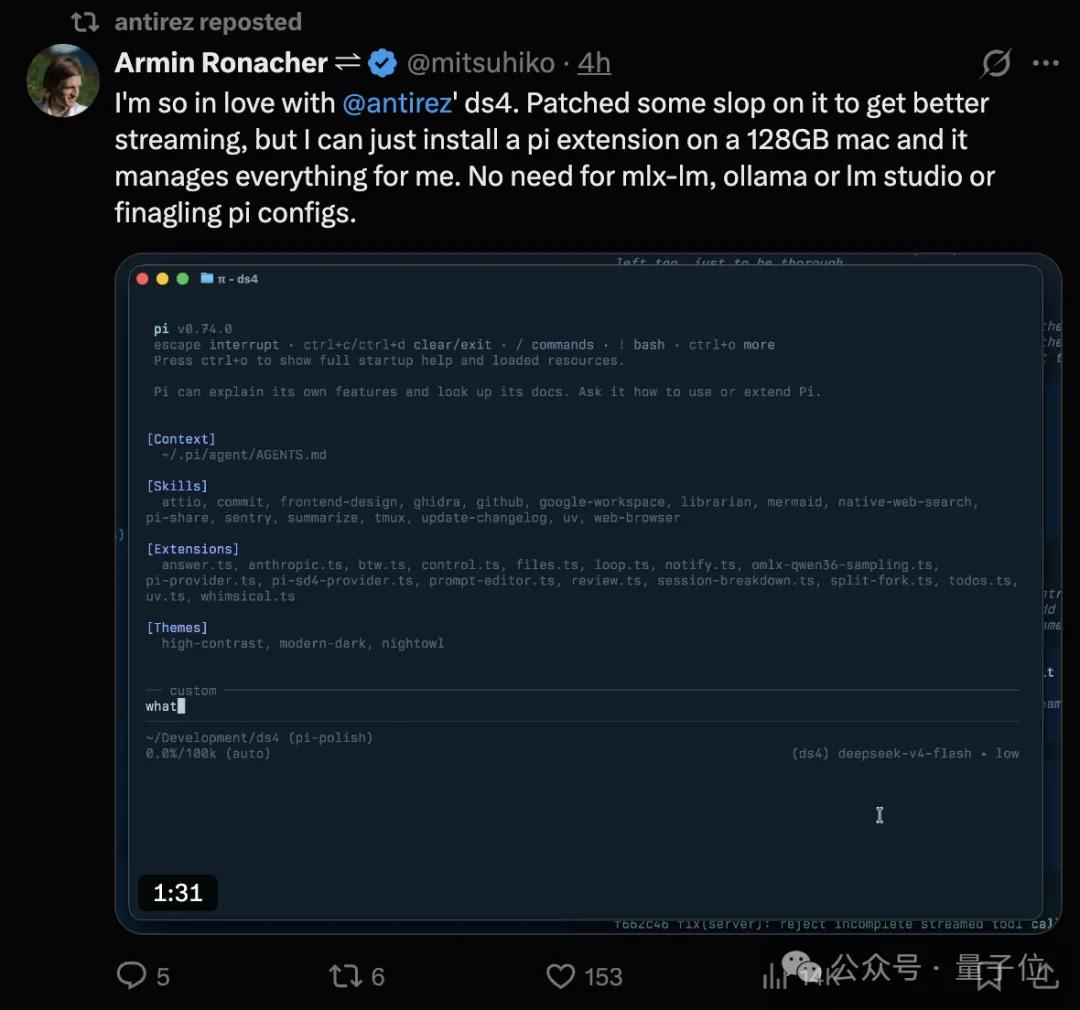
Regarding the motivation behind this, Antirez explains that while there are many excellent projects in local inference, attention is quickly diverted to the next model as new ones are released.
General engines must abstract to accommodate all models, which leads to compromises. What he aims to create is a deliberately narrow path, betting on one model at a time, validating with official logits, conducting long context tests, and integrating enough agents to confirm it is genuinely usable.
Once the framework was released, many users reported successfully running it on their Macs.
Are you ready to run V4 locally?
One Model, One Inference Framework
This development has sparked a larger discussion in the developer community:
Will we see a future where each model has its own inference framework?
A highly upvoted comment on Hacker News suggested an interesting direction: what if we start building hyper-optimized inference engines targeted at specific GPU and model combinations?
As GPUs become increasingly expensive, removing enough abstraction layers and directly coding for specific hardware and models could lead to significant optimizations.
However, this path has clear costs. As another comment pointed out, once a model becomes outdated, everything has to be rebuilt from scratch.

Antirez himself acknowledges this issue. He states that ds4 currently bets on DeepSeek V4 Flash, but the model may change.
The unchanging constraint is that local inference must run reliably on high-end personal machines or Mac Studios, starting with 128GB of memory.
What the future holds is hinted at in the README.
Currently Metal-only, there may be plans for CUDA support in the future. However, he writes cautiously that it may happen, but that’s all. This project deliberately remains small, fast, and focused.
More importantly, he presents a viewpoint in the README that local inference should be done well in three aspects, out of the box.
An inference engine with an HTTP API, a GGUF tailored for this engine and its assumptions, and a set of tests and validations integrated with coding agents.
This is a full-stack local inference approach, not just piecing together components but designing the entire chain as a product.
If this path proves successful, it could change the way local inference is approached.
When model vendors release new models, someone in the community will jump in to create a dedicated engine, specialized quantization, and agent integration for it. Each generation of models could have its own “antirez.”
Ds4 also has a candid detail. The README includes a statement that this software was developed with the “strong assistance” of GPT 5.5, with humans responsible for ideas, testing, and debugging.
Antirez states, If you do not accept AI-assisted development code, this software is not for you.

In just two weeks, from forking llama.cpp for adaptation to writing a dedicated engine from scratch, AI assistance has been crucial. This aspect may be even more noteworthy than ds4 itself.
One More Thing
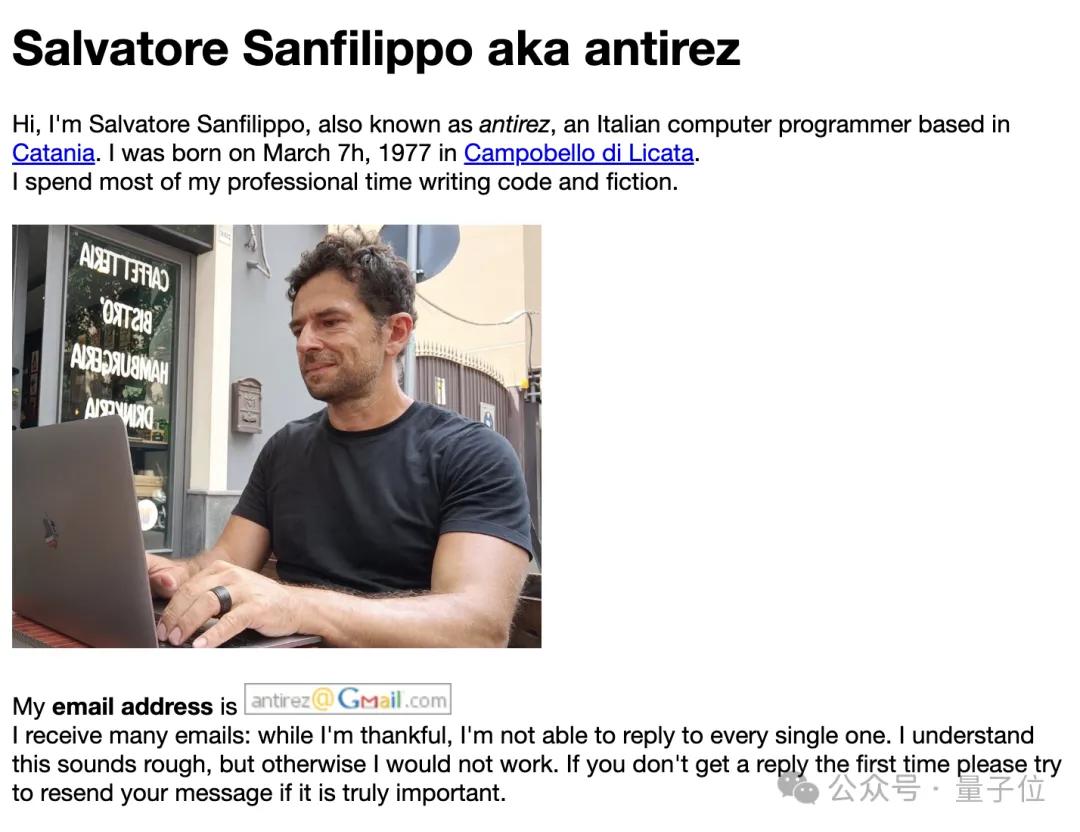
Finally, let’s talk about Antirez.
His real name is Salvatore Sanfilippo, born in 1977 in Sicily. He created Redis in 2009 and led the project for eleven years before leaving in 2020.
When he left, he wrote that he programs to express himself, viewing code as a product rather than just a useful tool. He would rather be remembered as a bad artist than a good programmer.
In late 2024, he returned to Redis in an evangelist role.
Beyond Redis, he has also created Kilo (a text editor with less than 1000 lines of C code), dump1090 (an aviation ADS-B signal decoder), and linenoise (a micro replacement for readline).
He has also been playing with Flipper Zero, writing RF protocol analysis tools, and porting Asteroids to it. In 2022, he published a science fiction novel titled “WOHPE,” focusing on AI, climate change, programmers, and the interaction between humans and technology.
The first line of his personal homepage states, “I spend most of my professional time writing code and writing novels.”
Regarding the birth of Redis, he wrote:
My wife said that in the early years of Redis, I wrote most of the code sitting on the toilet with a MacBook Air 11 inch. I wish I could say she was wrong, but she is completely right.
This tone permeates all his projects: small, precise, and self-contained.
Ds4.c follows the same path.
Take a look at his note in the ds4 README about macOS bugs, and you can immediately sense his personality.
Ds4 includes a CPU inference path for correctness verification, but the current version of macOS has a bug in its virtual memory implementation that causes kernel crashes during CPU inference.
He wrote, “Remember? Software is terrible. I can’t fix the CPU inference to avoid crashes because I have to restart the computer every time, which is not fun at all.”
Then he added, “If you have the guts, come help us.”
He also left a note on his personal homepage:
Modern programming is becoming complex and uninteresting, full of layers to glue together. It is losing much of its beauty. Most programmers are neither facing the artistic side of programming nor the advanced engineering side.
From Redis to ds4.c, fifteen years have passed, and Antirez remains the same Antirez.
Only this time, he has started paving the way for AI.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.