Introduction
On April 2, AMD Senior Director Stella Laurenzo presented a set of Claude Code logs, revealing 6,852 conversation files, 17,871 thought blocks, and 234,760 tool calls. The conclusion was clear: Claude’s judgment in complex tasks has begun to shallow. For the first time, heavy users had data to support their feelings; while the price remained unchanged, the experience was deteriorating.
Performance Decline
The focus on Claude is not just a typical fluctuation but a continuous degradation of task performance observed over several weeks. In engineering tasks, the model would stall at critical points, provide shallower solutions, and lose patience in long-chain reasoning. Stella’s audit detailed this change, noting that since February, the depth of thought has declined, and the density of reading and writing has also dropped. The assistant, once willing to delve into problems, has started to conserve effort.

Benchmarking and User Reactions
This issue has been exacerbated not only by the subjective experience but also by third-party benchmarks that have solidified these changes. In BridgeBench, the accuracy of Claude Opus 4.6 dropped from 83.3% to 68.3%, and its ranking fell from second to tenth. When a model is still sold at a high price but suddenly drops in rankings, users’ first reaction is not to think it’s an accident but to question whether they are overpaying.
Changes in User Experience
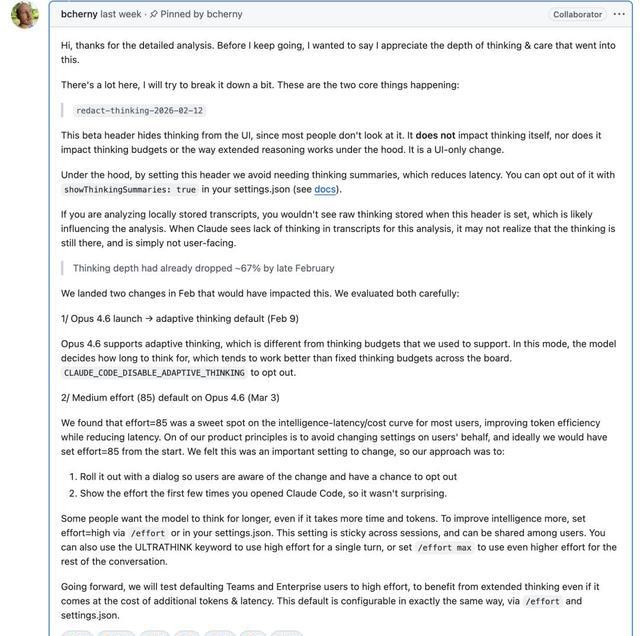
More glaring is the simultaneous change in the interface and backend. After February, the thought process was hidden from the front end, causing many users who closely monitored the reasoning chain to lose their observation window. The backend also reduced the cache duration of prompts from one hour to five minutes. In long conversations, any pause could lead to cache invalidation, accelerating consumption. While this appears to be a speed optimization, the user experience suggests otherwise.
The discontent is not isolated; engineers, coders, and workflow operators have provided consistent feedback: complex tasks are slower, and long tasks are more prone to interruptions. Boris Cherny’s explanation was straightforward, stating that the default effort level has been set to an ‘average effort’ mode of 85 points, officially aimed at balancing speed and computational costs for faster responses to more users.
Billing Changes
This explanation has not quelled the unrest, as heavy users focus on results rather than rhetoric. Users can accept a slower pace but struggle with instability under the same subscription, especially when a paid product begins to actively conceal its thought processes. Users may feel they are paying for capability but receiving a throttled version instead.
The controversy extends to billing as well. Anthropic has shifted its enterprise billing from a fixed monthly model to a structure based on seat fees plus actual usage, resembling a usage-based billing logic. The fixed portion is $20, with the remainder calculated based on actual consumption. Companies that previously paid around $200 monthly for high-frequency use may see their bills double or even triple under the new rules.
Rising Costs and User Experience
The Information highlighted another reality: reasoning costs have tripled over the past year, with pressure on enterprises stemming from computational costs rather than emotional factors. The issue lies in the fact that while rising costs are real, the compression of user experience is equally tangible. Enterprises face their own gross profit pressures, while users contend with productivity pressures. The convergence of these two pressures sharpens the controversy.
In response, OpenAI has launched a $100 tier for its Codex subscription service, seemingly addressing the dissatisfaction directly. It is well-known that there are no gaps in the AI programming market; if one provider’s pricing, stability, or controllability falters, customers will begin to explore alternatives.
Systemic Issues
The most noteworthy aspect of this controversy is not the term “diminished intelligence” itself, but the systemic issues behind it. If a model defaults to a lower effort level, conceals the thought process, compresses cache time, and shifts enterprise billing to variable rates, these technical and commercial adjustments collectively represent a design that shifts cost risks onto users.
Another line that many initially overlooked is that Anthropic is preparing to launch Claude Opus 4.7. This new flagship model is being showcased alongside an AI design tool capable of generating web pages, presentations, landing pages, and product prototypes using natural language. This move signals a clear intent to broaden the product line beyond coding into design and collaboration.
The reactions from the app and software sectors have also been swift, with stock prices of design software giants like Adobe, Wix, and Figma dropping by over 2% within hours of the announcement. The capital market’s response is often more direct than discussions in comment sections; it does not debate whether the model is genuinely experiencing “diminished intelligence” but focuses on whether new universal tools will encroach on existing software entry points.
Conclusion
At this stage, the controversy is no longer just a Claude-specific issue. Over the past few months, the AI industry has been grappling with the same challenge: high computational costs, user demand for stability, intelligent models, and profitable products are nearly impossible to balance simultaneously. Thus, we see one side demanding high-effort modes while the other side cuts costs, new models iterate rapidly, and pricing structures continually evolve.
Stella’s audit is memorable not for amplifying emotions but for breaking down time, samples, and behaviors. The 6,852 conversations, 17,871 thought blocks, and 234,760 tool calls may not be glamorous numbers, but they are solid enough to transform “feeling worse” into “more evidence,” which is its weight.
Looking deeper, the issue raised by Claude is not just about fluctuations in model performance but whether a platform should be allowed to adjust “intelligence levels” quietly. Users purchase subscriptions expecting stable performance, not minor adjustments hidden in a black box. Prices can change, functionalities can shift, and calling strategies can be modified, but if even the user experience is not communicated in advance, trust will erode.
The emergence of Opus 4.7 indicates that Anthropic has not halted its repair and iteration efforts, with officials outlining new performance directions aimed at complex multi-step coding, workflow proxies, and tool error rates, all pointing toward more practical upgrades. The remaining question is whether these upgrades can restore balance from the previous phase or merely retell the efficiency narrative in the new version.
Currently, the controversy surrounding Claude is unlikely to resolve quickly. The reasons are straightforward: users seek certainty while vendors face cost curves. Benchmarks, logs, pricing, and product rhythms all lay this tug-of-war bare. Moving forward, what truly matters is not how much it claims to have improved, but whether heavy users are still willing to entrust it with their most challenging tasks.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.